You’ve likely seen it before: something with no specific ownership between a group of people falling into disrepair. It could be a shared kitchen in a house that nobody keeps clean, a communal garden that is overgrown, or a shared path that is constantly littered with rubbish.
It seems that despite our best efforts to desire to be altruistic and to do the right thing, we often fail to do so when there is no specific ownership. In fact, this happens in software all the time. Shared codebases that grow in complexity and become a tangled mess, shared infrastructure that nobody wants to touch, and shared processes that nobody wants to own.
There is a name for this phenomenon: the tragedy of the commons. The definition states that should a group of people have access to a shared resource, they will act in their own self-interest and deplete that resource, even if it is not in the group’s long-term interest to do so.
Up and Down but Not Sideways
Another tragedy of the commons situation is that of your peer group when you are in middle management. While it is true that your peers are the people who are in the same position as you, also with the same manager, the implied closeness and camaraderie that this should bring is often lacking.
In fact, it is more than just lacking: it can be nonexistent. This is because the default outlook for middle management is to look up and down the org chart, but not sideways. Because you are so focused on your own team and your own manager, you often forget that you have a peer group at all! That is, until you need something from them. At this point, the underinvestment in your peer group becomes apparent: you have limited rapport and trust with them, and an ask to transfer some of your engineering capacity to them is met with hot flushes and heavy and furious typing.
This is the tragedy of the common leader: despite you and your peer group having the same leader in common (i.e. access to the same resource), you act in your own self-interest, even if it is not in the group’s long-term interest to do so. We can see how this situation can play out in the following diagram.
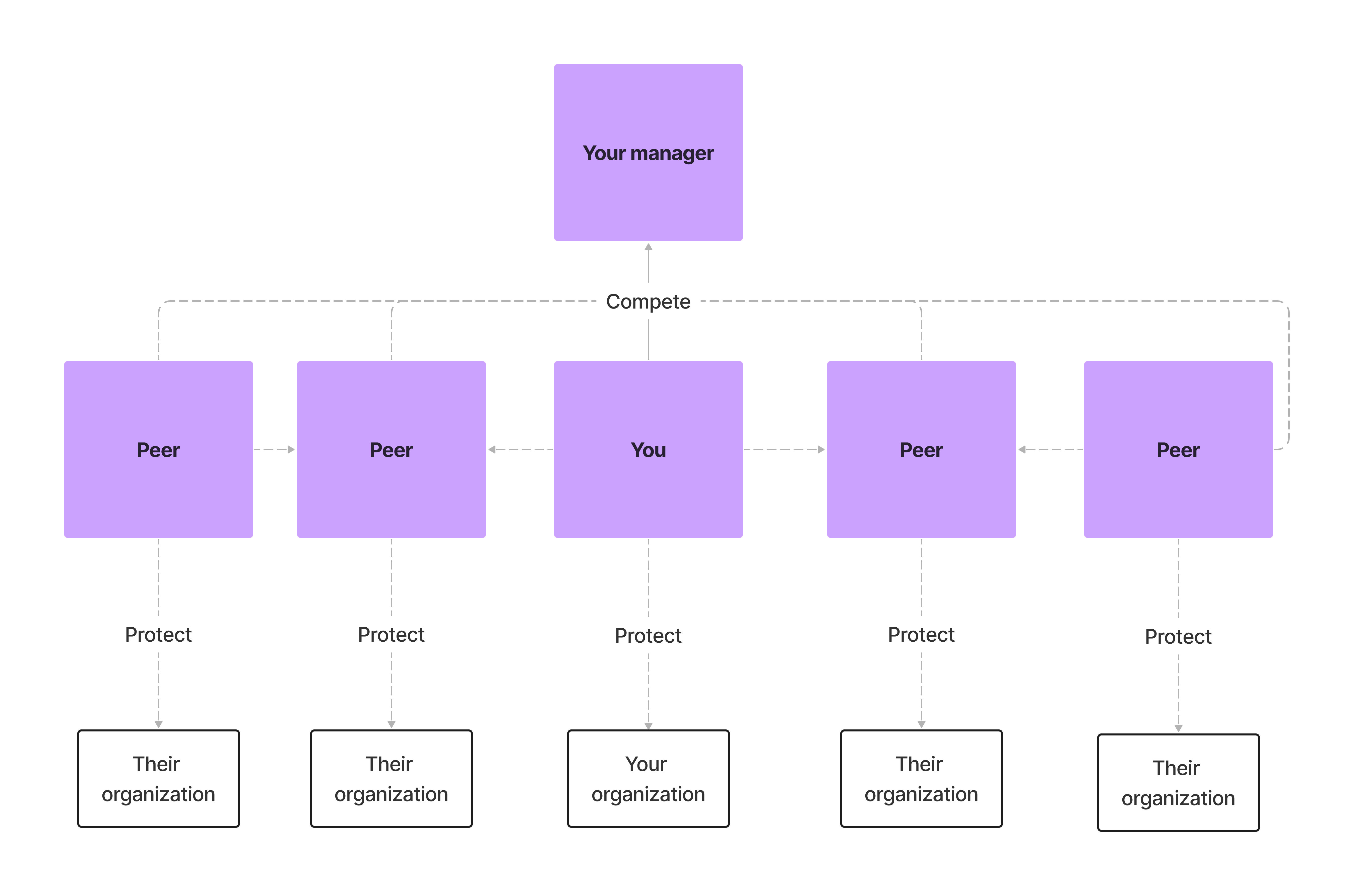
Assuming a situation where there is a dysfunctional relationship between you and your peer group, the story goes a little something like this:
- The manager is the common resource that you and your peer group have access to. Since you are acting in a tragedy of the commons, you compete with your peer group for your manager’s time, attention, and favor. You want to be the top performer that gets the most resources from the commons.
- This in turn creates a hostile competitive environment. Like the shared codebase or the shared kitchen, you want everything for yourself. You see your peers as competition, and you, therefore, communicate and collaborate with them as little as possible. You don’t want to give them any advantage over you.
- You also protect your team at all costs. You see your team as your own personal resource, and you don’t want to give any of it away. They do the same, and slowly but surely you create a siloed environment that doesn’t play well with others.
Is it any wonder that shared codebases degrade when the organizations that look after them are like the ones in the diagram? Is it any wonder that middle management is lonely when your peers are your competition?
We may have just identified why so many organizations are completely dysfunctional. The tragedy of the commons is everywhere. But what can we do about it?
Magnetism and Polarity: Pulling Peers Together
The solution, clearly, is to strengthen the relationships that you have with your peers so that you can create a home team that you all feel a part of and that you can all rely on to help you achieve your collective goals. No surprises there.
If this was an article about being an individual contributor at the beginning of your career, this section would be easy: it would encourage you to do your best in your role and make sure that you spend time connecting with your peers in your team individiually as well as working together every day. The rest would take care of itself as you all belong to the same team and are working on the same goals; your collective direction is clear, and there is little room for conflict.
However, as we described in the previous section, you exist both in collaboration and in conflict with the other areas of the organization, which in turn means that you also exist in collaboration and in conflict with your peer group. Given the breadth of the area that you, your peers, and your manager cover, you may not find that there is a lot pulling your peer group together naturally. Additionally, you may find that you are all so busy that if you don’t have compelling reasons to connect, then you simply won’t; your time will be better spent elsewhere.
Your job, therefore, is to create more compelling reasons to connect. The only true compelling reason is that both you and your peers are getting something valuable out of the relationship. The good news is that there often always is something valuable, but you need to put a bit of work in to find it.
Attraction, Repulsion, and the Middle Ground
Typically in senior leadership roles the organization that you are running will have various first and second order effects on other areas. This could be because you are buildings tools or APIs that are consumed by other teams, or it could be that you are building new product functionality that is requiring other teams to change their systems in order to enable yours.
A model that you can use to think about the effect that your organization has on others is that of polarity. Magnets have a north pole and a south pole, and depending on which way you hold them, they will either attract or repel each other. The same is true of your organization: you will either attract or repel other teams depending on your polarity.
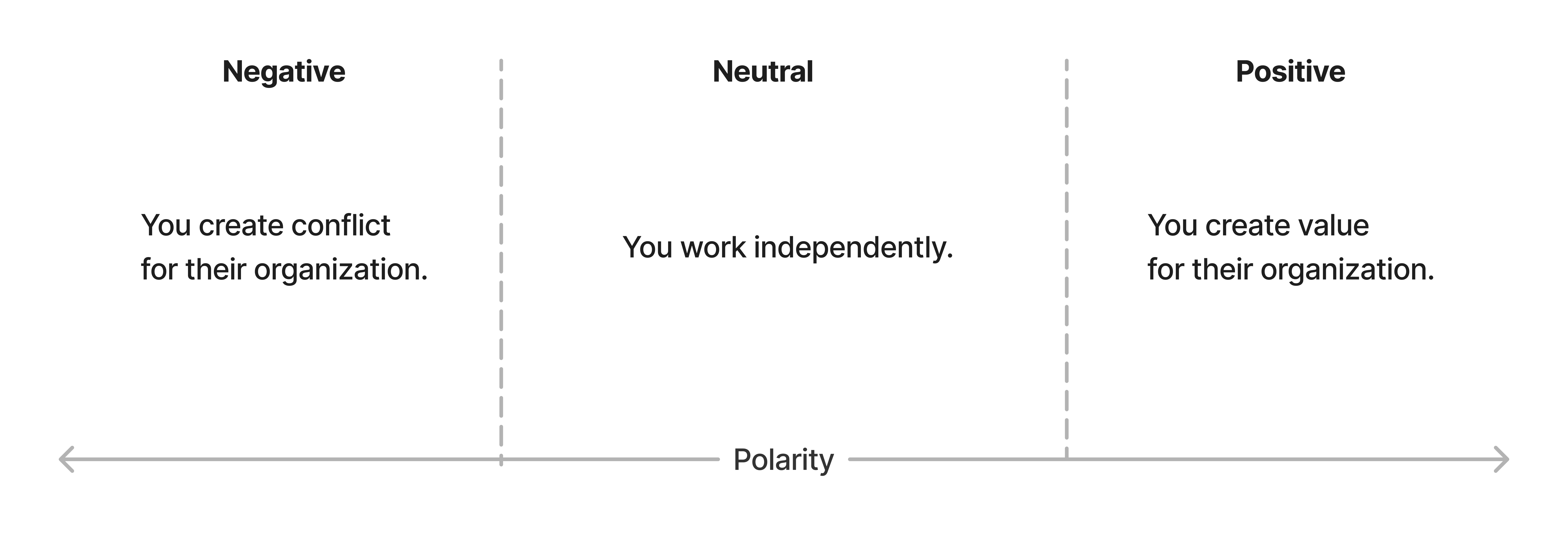
But what do we mean by that? The polarity of your organization is determined by whether you are generating value or conflict for other teams. If you are generating value, then you are attracting other teams to you: they want to work with you because you are making their lives easier. If you are generating conflict, then you are repelling other teams: they want to avoid you because you are making their lives harder.
As an example of positive polarity, imagine that your team is building a new API that other teams can use to generate product recommendations for users. This API is going to make it much easier for other teams to build new smart features, and so they are going to be attracted to you: you’re producing things that they want, and you’re being an enabler for them.
An example of negative polarity is where your ideal product direction is to overhaul the UX of an area of the product that you don’t own in a way that conflicts with the ideal product direction of the team that does own it. Here, you’re going to be repelling the other team: you’re making their lives harder, and they may want to escalate this conflict so that you change your direction.
A middle ground also exists of neutral polarity. This is where you are neither generating value nor conflict for another team. This could be two teams that are doing their own thing independently, with zero overlap. They coexist happily with no need to interact.
Depending on whether you are generating value, conflict, or are neutral, you can benefit from different approaches to building relationships with your peers:
- Take the polarity model and look at your peer group and the areas of the organization that they are responsible for. By peer group, we typically mean the other people that report to your manager, but you may also want to include other people in your organization that you work with regularly.
- For each area, determine whether you are mutually generating value, conflict, or are neutral. It may be that for some of your peers you generate both value and conflict.
- For every peer’s organization that you are generating value, think about whether their organization is fully aware of that value that you are generating. For example, are they aware of the APIs or new features that you are building that they can use? If not, how can you make them aware?
- Now, for every peer’s organization that exists in conflict, reflect on how that conflict is caused and where it typically shows up. Is it due to a lack of communication, or is it due to fundamental strategic differences? If it’s the former, how can you improve communication? If it’s the latter, how can you resolve the conflict?
- Finally, for every peer’s organization that you are neutral with, consider whether that is intentional or not. Are there ways that you could collaborate or communicate more effectively with them in order to move from neutral to positive polarity?
Polarity-Led Relationships
Given that we can categorize the polarity of our organization with that of our peers, we can then use this to determine how we should approach building and maintaining relationships with them. The table below gives some example traits and talking points for each polarity. There are many more that will uniquely evolve from your own situation, but this should give you a good starting point.
| Polarity | Relationship traits | Talking points |
|---|---|---|
| Positive | Your team actively collaborates with this team in order for them to get their job done. | Share knowledge with each other from both sides of this collaboration. What’s going well? What’s not going well? What can be improved? Focus on ways to increase the output of this existing collaboration. |
| You are actively building things that this team wants to use that they can’t build themselves. | Use your time together to demo new features or APIs that you are building that they could use. Get their feedback and see if they can become early adopters that can offer feedback to improve these systems or features. See the other team as a multiplier of your impact. | |
| Your team enables this team to do their job such as by providing tooling, APIs, or infrastructure. | Discuss their experience with the tools that your team provides. See whether they can show you how it’s being used, and what their pain points are. Offer routes for those pain points to be fixed. | |
| Negative | Your team builds in a direction that strategically collides with this team. | Be open about that fact, and understand what their direction is versus yours. Build empathy between both sides and see whether you can make the way forward easier. Regardless of strategic clashes, ensure that you are a trusted collaborator, even if you may have fundamental disagreements. Make your stance well understood. |
| Your team has difficulty collaborating because of technical, interpersonal, or process-driven reasons. | Use the relationship as a means to understand why this is the case, and see whether both parties can change the way that they are collaborating to make the situation better. Challenge yourselves to work together to fix this. | |
| Neutral | Both teams rarely interact because they are working on unrelated things. | Use this as an opportunity to build trust and rapport for the future. Use your interactions as an opportunity to share what both sides are working on as this context may be useful later on, or present opportunities for positive polarity that you didn’t know existed. |
Take some time to think about how you can lean in and make your peer group more cohesive, collaborative, and effective. Don’t wait for your manager to do this for you: you can make it happen yourself.