Parkinson’s Law states that “work expands so as to fill the time available for its completion.” Although it is counter-intuitive, you will find that through practice and experience, there is a lot of truth to this. Projects that don’t have deadlines imposed on them, even if they are self-imposed, will take a lot longer than they need to, and may suffer from feature creep and scope bloat.
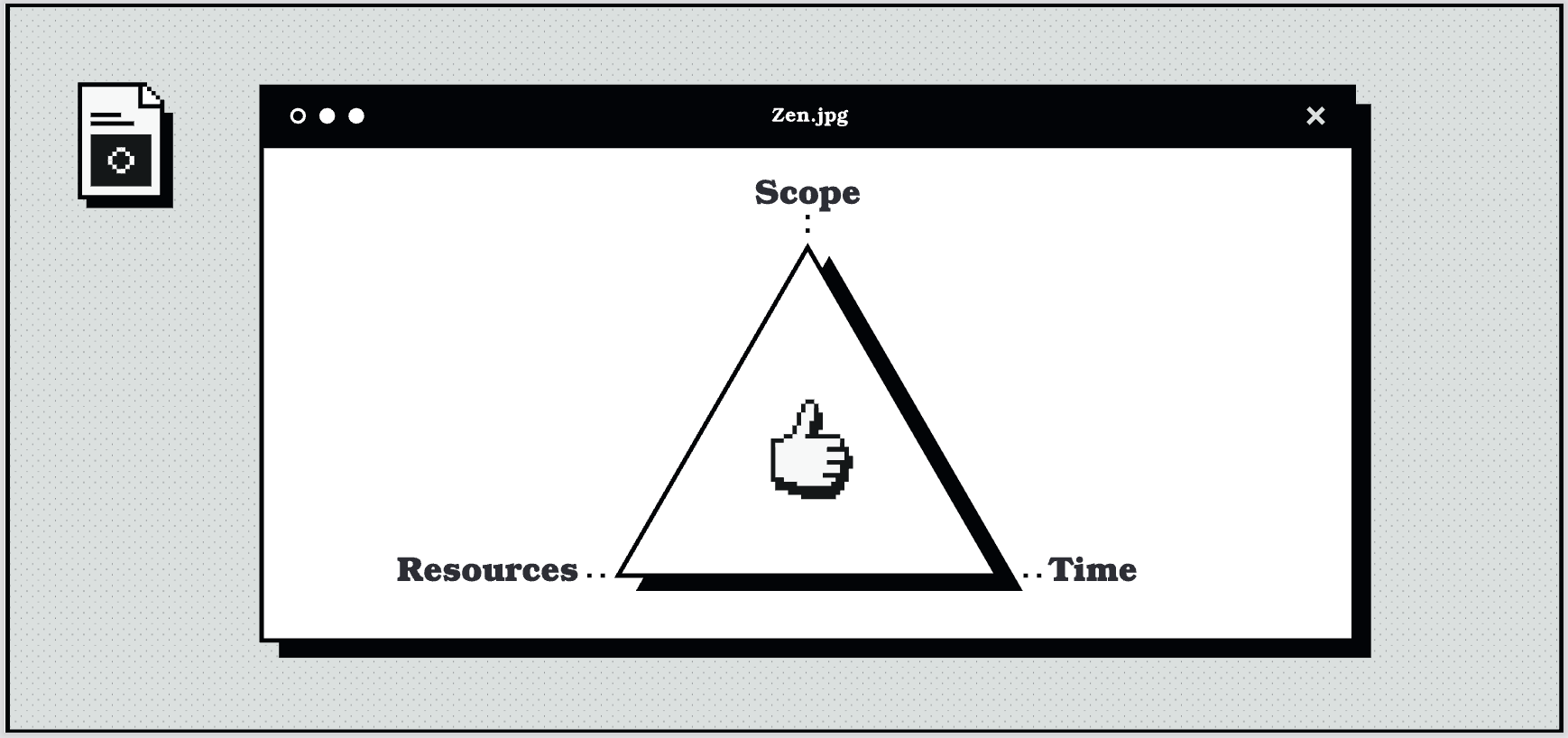
By setting challenging deadlines you will actually get better results. It’s all about manipulating the Iron Triangle of scope, resources, and time.
If you’ve not come across the Iron Triangle before, the idea is that it represents the three key constraints of a project:
Scope, which is the work that needs to be completed.
Resources, which are the people and tools that are available to do the work.
Time is, unsurprisingly, the amount of time that you have to get it done. Who’d have thought?
You can’t change one without affecting the others. For example, if you want to do more work, then you’re either going to need more people or more time. It’s the embodiment of the “pick two” rule: you can have it good, fast, or cheap, but you can’t have all three.
Back to Parkinson’s Law: without tight time constraints, the scope of a team’s project will expand to fill the time available. This is just human nature. Just look at how long my clean washing sits in the basket before I actually put it away, or how long those little DIY jobs around the house take to get done. With no deadline, there’s no urgency, and so things just don’t happen.
So, deadlines work. Now, the usual hip-shoot counter to deadlines is that “fake” deadlines lead to poor work being done, and, look: there is sometimes truth to that. However, that situation occurring typically represents poor application, rather than issues with the methodology. Putting challenging timeboxes on projects in a healthy environment can lead to serious innovation and creativity. Doing the same with impossible timeboxes in a toxic environment will lead to all of the bad things that you expect.
Deadlines really help human beings get things done. The only way that I’ve written books is because I set myself a challenging, but not impossible, schedule with the publisher. This contract of external accountability keeps the fire going through the long slog, and it forces me to make clear-cut decisions about what to include, what to leave out, and how to manage my spare time so I make progress. The exact same thing is true with communication and software projects.
When you are asking people to do something, lead with a recommendation of when it should be done by. Be explicit about this, but open to negotiation. It’s such a simple technique, but when you compound its usage over a year at a big company, you will be amazed at the difference it makes.
Deadlines force a clear tempo and cadence and, fundamentally, they make things happen. A canonical example of this is sending round a survey that can be filled in whenever versus one that needs to be filled in by tomorrow: just by asking, you will get a much higher response rate far faster. Learn from this, and apply it to your own communication.
This tempo and cadence is crucial for effective leadership. Even though you may not think that people want it, and even if people themselves think they don’t want it, knowing that things need to be done by deadlines that are just on the cusp of the comfort zone forces real, tangible progress. If you think that a prototype might take a month, why not challenge the team to see what they can deliver by the end of the week? You will be surprised, and so will they.
To get started, be aware that humans always underestimate what they can get done in one week. See how many teams, projects, and tasks that you can inject a weekly reporting cadence into: have teams plan, execute, and report on what they’ve done weekly, writing up their progress in an update that is shared widely in a place that anyone can see. This discipline is energy-giving, and soon you will find that it completely reshapes how people think about their work. Your staff will actively look forward to getting things done so they can write up and share their progress each Friday afternoon.
When wielded with grace, good intentions, and knowledge of what gets humans moving and feeling good, deadlines are a powerful tool. Parkinson’s Law is real, and you will need to fight it harder the larger your organization is. If you can succeed in this fight, you can grow and still ship fast with an org size of tens of thousands. If you don’t, then one day you’ll look around and wonder why your startup turned into the software equivalent of local council’s tax office.
One of the most powerful groups that you can be part of as a senior leader is a trifecta. A trifecta is a group of three people from different disciplines who work together to achieve a goal. Typically, this is a group consisting of engineering, product, and UX.
Engineering is responsible for building the product, that is, writing the lines of code that make it work.
Product is responsible for defining what the product should do, that is, what features it should have and how it allows a user to achieve their goals.
UX is responsible for designing how the product should work, that is, how the user interacts with it and how it looks.
With these three disciplines working together, you have a powerful combination of skills and perspectives that can create a product that is scalable, useful, and beautiful.
We often think of trifectas as being an artifact of a single front-line team, rather than anything to do with senior management. For example, a team may have a product manager, a UX designer and a number of engineers that report to a single engineering manager. The three disciplines work together to define, design, and build the product, and in doing so, they experience positive tension that helps them to make better decisions.
For example, some of these trade-offs can be:
Scope versus effort. Engineering might emphasize building robust, extensible solutions, while Product might prioritize faster delivery to validate a hypothesis of product-market fit first. The right balance will be up for debate.
User needs versus technical constraints. Product or UX may advocate for a feature that is simple to use but highly challenging to implement, while engineering may advocate for a simpler solution that is easier to build and maintain with a less optimal user experience.
User education versus product simplicity. Product may advocate for a feature that is complex and customizable but powerful, while UX may advocate for a simpler solution that is easier to understand and use by the majority of users.
These trade-offs and debates are not bad: they are in fact extremely healthy. They force the team to make better decisions and in doing so, they create a better product.
In terms of their responsibilities, a team’s trifecta will:
Ensure strategic alignment. The trifecta will work together to ensure that the team’s work is aligned with the wider organization’s strategy. They will also ensure that the team’s work is aligned with the work of other teams, identifying and resolving gaps or overlaps.
Define the team’s roadmap. The trifecta will facilitate the idea generation process, and then work together to define the team’s roadmap. This includes getting the right balance between new features, technical debt, UX improvements, and other work.
Make decisions. The quality of the work outlined in the bullet points above is dependent on the quality of the decisions that the trifecta makes. Daily, weekly, monthly, and quarterly, the trifecta will make decisions about what needs prioritizing, what needs to be cut, and what needs to be changed.
Drive up the execution of their individual crafts. Achieving excellence in engineering, product, and UX does not happen by accident. It requires a concerted effort to ensure that the team is constantly improving in each of these areas in balance with delivering the roadmap, and each member of the trifecta will represent their craft. For example, the engineering lead will have an eye for scalability, resilience, and performance, while the UX lead will have an eye for usability, accessibility, and aesthetics.
Resolve escalations and blockers. The trifecta will be the first port of call for any escalations or blockers that the team encounters. They will work together to resolve these issues, and if they can’t, they will escalate to the next level of management.
Communicate with stakeholders. The trifecta is responsible for communicating with stakeholders, including other teams, senior management, external partners and users, and other parts of the organization. They will work together to ensure that the right information is communicated to the right people at the right time.
However, there is something important you need to consider as a senior leader: even if you have clearly defined trifectas for each of your teams, a critical bug that creeps into organizations is that healthy, collaborative trifectas are only found within the front-line teams and nowhere else. This is a problem, but you can fix it.
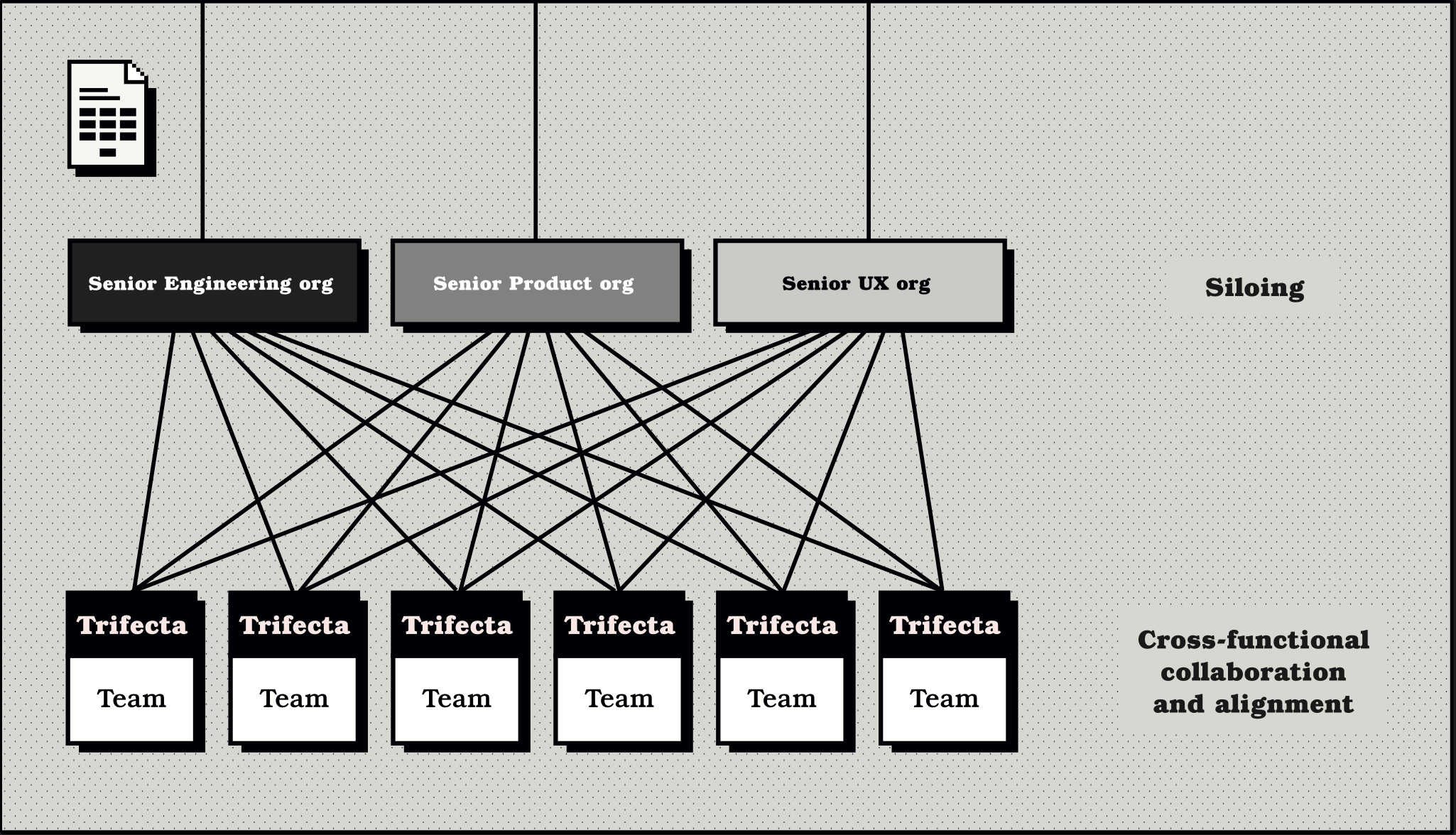
Lack of Trifectas = Increase in Siloing
In many organizations, as you progress up the org chart, trifectas, along with their benefits, disappear.
This happens because typically organizations form their reporting lines around each discipline: engineering managers report into Directors of Engineering, VPs of Engineering and beyond, and the same is true for Product and UX. Now, it’s worth stating that there is nothing wrong with this at all. In fact, it’s a great way of ensuring that each discipline has a clear career path, and that each discipline has a clear voice at the senior levels of the organization.
However, it does mean that the trifecta structure and the positive tension that it brings can be lost, and senior leaders become isolated from all of the benefits of cross-functional collaboration. At best, this is a missed opportunity. At worst, it can lead to a dysfunctional organization.
Looking at the following diagram, we can see what happens when trifectas are only found within the front-line teams. Where they exist, we get the cross-functional collaboration that we want, but as we move up the org chart, we lose it.
The result is that the senior leaders are isolated from each other as part of warring factions, leading to dysfunctional behavior such as:
Lack of visibility. Senior leaders only view the world through the lens of their own discipline. They are not exposed to the perspectives of other disciplines, and as a result struggle to make decisions in the same unified way that the front-line trifectas do.
Lack of alignment. The lack of visibility leads to a lack of alignment between the different disciplines because they are not jointly accountable as part of a trifecta. For example, senior engineering leaders may only hear that not enough technical debt is being paid down, leading to a myopic, unbalanced view of the work that is being done. This leads to increased tension and conflict between the disciplines as a whole.
Lack of accountability. While each trifecta-led team is wholly accountable for the work that they do and managing the trade-offs between the disciplines, the senior leaders are not: they are only accountable for their own discipline. This makes it far harder to make decisions that span the org chart: it can feel like an adversarial situation where each discipline is trying to get the best deal for themselves. This is not the behavior of senior role models: they should unite rather than divide.
Lack of escalation paths. When a trifecta-led team encounters an escalation or blocker that they cannot resolve themselves, they need a route to escalate it to the next level of management. However, if the next level of management is not part of a trifecta, then the escalation path is unclear.
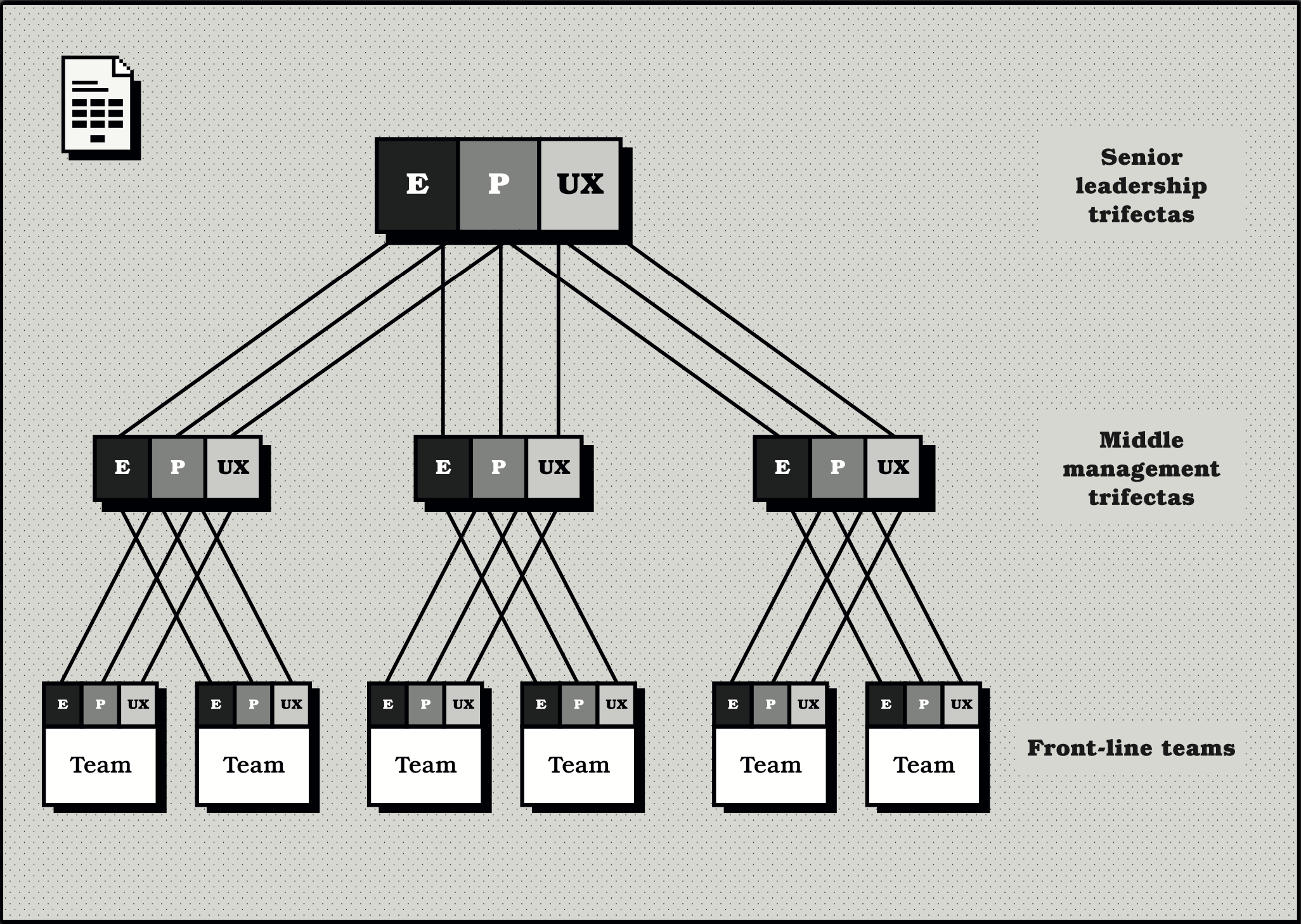
As such, it is in your best interest to ensure that trifectas are present among the senior leadership team and middle management in the same way that they are present in the front-line teams. Not only does this work against the above problems, it also helps to ensure that the senior leadership team is unified behind a common goal and that they are able to make decisions that are aligned with the long-term strategy of the organization, not just their own discipline.
The following diagram shows what this might look like. In it we can see that the trifectas are present at all levels of the org chart. Every front-line team ladders up to a more senior trifecta, and these in turn ladder up to trifectas at the executive level. This means that the trifecta structure is present everywhere, and that the benefits of cross-functional collaboration are present everywhere too.
It is worth mentioning that this trifecta organizational structure is not the same as reporting lines. Therefore, it doesn’t matter if the reporting lines of senior managers line up directly with the trifecta ownership structure. What matters is that the trifectas are defined, present, and accountable for the areas that they oversee.
For example, if a large technology company develops multiple products, each with tens of front-line teams, then you would expect to see a trifecta for each of those products that those teams work on, with all of the front-line teams laddering up to those senior trifectas. Above them would be the most senior trifecta, which would be responsible for the entire product portfolio.
There are many benefits to having trifectas all the way up the org chart:
Accountability is clear. Each trifecta is accountable for the work that they oversee, and each piece of accountable work has a clear cross-disciplinary group of owners. They vouch for the product and the company first, not their own discipline.
Positive tension is present at all levels. Each trifecta is responsible for managing the trade-offs between the disciplines, and this positive tension is present at all levels of the org chart. This means that the decisions that are made are more likely to be balanced and well-considered in the same way that they are in the front-line teams.
Escalations are resolved quickly. If a front-line team encounters an escalation or blocker that they cannot resolve themselves, they can escalate it to the trifecta that they ladder up to. If that trifecta cannot resolve it, they can escalate it further, and so on, until it reaches a trifecta that have the accountability and authority to resolve it.
The trifecta structure maps neatly to the roadmap and project approvals. It is a natural fit for this process. Every trifecta will own their own piece of the roadmap, and senior trifectas own the roadmap for broad areas. Overlaying the escalation process on top of this means that the trifecta structure is also a natural fit for project approvals, resourcing debates, and other prioritization discussions.
Ensuring that you have trifectas all the way up the org chart is one of the simplest and most effective ways of raising accountability, improving decision-making, and ensuring that everyone is unified around a common goal while vouching for their own disciplines in a way that is healthy, constructive, and filled with positive tension.